Exploring BigData Analytics Using SPARK in BigData World
BigData Project List
Spark was developed in 2009 at UC Berkeley AMPLab, then open sourced in 2010, Spark has since become one of the largest OSS communities in big data,with over 200 contributors in 50+ organizations.
“Organizations that are looking at big data challenges –including collection, ETL, storage, exploration and analytics -should consider Spark for its in memory performance and the breadth of its model. It supports advanced analytics solutions on Hadoop clusters, including the iterative model required for machine learning and graph analysis.”
By Gartner, Advanced Analytics and Data Science (2014)
As we know that Spark came into picture after Hadoop, so let see why Spark is more popular and why spark is different from Hadoop.
Industries are using Hadoop extensively to analyze their data sets. The reason is that Hadoop framework is based on a simple programming model (MapReduce) and it enables a computing solution that is scalable, flexible, fault-tolerant and cost effective. Here, the main concern is to maintain speed in processing large datasets in terms of waiting time between queries and waiting time to run the program.
Spark was introduced by Apache Software Foundation for speeding up the Hadoop computational computing software process.
As against a common belief, Spark is not a modified version of Hadoopand is not, really, dependent on Hadoop because it has its own cluster management. Hadoop is just one of the ways to implement Spark.
Spark uses Hadoop in two ways – one is storage and second is processing. Since Spark has its own cluster management computation, it uses Hadoop for storage purpose only.
MapReduce use cases showed two major limitations:
1. difficultly of programming directly in MR
2. performance bottlenecks, or batch not fitting the use cases
In short, MR doesn’t compose well for large applications. Therefore, people built specialised systems as workarounds…

But here major drawback was that developers has to learn all these tool to perform specific tasks which was hard, time taking and expensive for developers.Each tool was built to
perform only its specific use cases.Single tool can not full fill ask of multiple use cases in Big data world.
perform only its specific use cases.Single tool can not full fill ask of multiple use cases in Big data world.
So Spark development has gave a relief to development community as Spark was good
enough as replacement for most of tools as Spark has so rich libraries that can be used in
different different use case.
Unlike the various specialized systems, Spark’s goal was to generalize MapReduce to support
new apps within same engine. Two reasonably small additions are enough to express the
previous models:
previous models:
• fast data sharing
• general DAGs
This allows for an approach which is more efficient for the engine, and much simpler for the end users.
Since the time of its inception in 2009 and its conversion to an open source technology, Apache Spark has taken the big data world by storm. It became one of the largest open source communities that includes over 200 contributors. The prime reason behind its success was its ability to process heavy data faster than ever before and it got possib;e due to its in-memory cluster computing that increases the processing speed of an application.
There are three ways Apache Spark can run :
Standalone – The Hadoop cluster can be equipped with all the resources statically and Spark can run with MapReduce in parallel. This is the simplest deployment.
On Hadoop YARN – Spark can be executed on top of YARN without any pre-installation. This deployment utilizes the maximum strength of Spark and other components.
Spark In MapReduce (SIMR) – If you don’t have YARN, you can also use Spark along with MapReduce. This reduces the burden of deployments.
Lets have a look on Mapreduce & Spark history::

Some key points about Spark:
• handles batch, interactive, and real-time within a single framework
• native integration with Java, Python, Scala
• programming at a higher level of abstraction
• more general: map/reduce is just one set of supported constructs
Key distinctions for Spark vs. MapReduce:
- unified engine for many use cases
- lazy evaluation of the lineage graph reduces wait states, better pipe lining
- generational differences in hardware off-heap use of large memory spaces
- functional programming / ease of use reduction in cost to maintain large apps
- lower overhead for starting job
- less expensive shuffles

Life Cycle of a SPARK Program:
1) Create some input RDDs from external data or parallelize a collection in your driver program.
2) Lazily transform them to define new RDDs using transformations like filter() or map().
3) Ask spark to chache any intermediate RDDs that will need to be resued.
4) Launch actions as count(), and collect to kick off a parallel computation,which is then optimized and executed by spark.
DAG/Lineages :Computations on RDDs are represented as a lineage graph, a DAG representing the computations done on the RDD. This representation/DAG is what Spark analyzes to do optimizations. Because of this, for a particular operation, it is possible to step back and figure out how a result of a computation is derived from a particular point.

How Spark Framework/System Works:
1) Create some input RDDs from external data or parallelize a collection in your driver program.
2) Lazily transform them to define new RDDs using transformations like filter() or map().
3) Ask spark to chache any intermediate RDDs that will need to be resued.
4) Launch actions as count(), and collect to kick off a parallel computation,which is then optimized and executed by spark.
Lazy evaluation means that when if we call a transformation or an action on an RDD (for instance, calling map()), the operation is not immediately performed. Instead, Spark internally records metadata to indicate that this typical operation has been requested. Rather than thinking of an RDD as containing specific data, it is best to think of each RDD methodology as consisting of instructions on how to compute the data that we build up through transformations phases. Loading data into an RDD is lazily evaluated in the same way transformations are done. So, when we call sc.textFile(), the data is not loaded until it is necessary things required. As with transformations, the operation (in this case, reading the data) can occur multiple amounts of times.
DAG/Lineages :Computations on RDDs are represented as a lineage graph, a DAG representing the computations done on the RDD. This representation/DAG is what Spark analyzes to do optimizations. Because of this, for a particular operation, it is possible to step back and figure out how a result of a computation is derived from a particular point.
E.g.:
val rdd = sc.textFile(...)
val filtered = rdd.map(...).filter(...).persist()
val count = filtered.count()
val reduced = filtered.reduce()

How Spark Framework/System Works:
1. master connects to a cluster manager to allocate resources across applications
2. acquires executors on cluster nodes –processes run compute tasks, cache data
3. sends app code to the executors
4. sends tasks for the executors to run

First thing that a Spark program does is create a Spark Context object, which tells Spark how
to access a cluster.In the shell for either Scala or Python, this is the sc variable, which is created automatically Other programs must use a constructor to instantiate a new SparkContext Then in turn SparkContext gets used to create other variables.
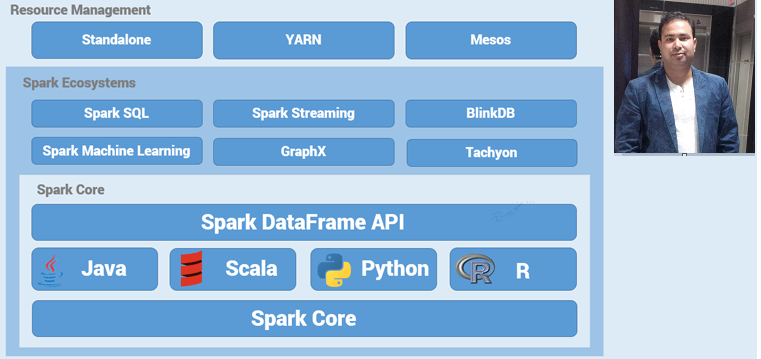
Lets understand the complete architectural view of Spark system from below diagram.
- In Center ,we have Spark which has API’s in SCALA,Java,Python,R
- 1st Outer circle talks about Sparks components which are SPARK SQL,SPARK Streaming,SPARK MLLIB,SPARK GRAPHX.
- 2nd outer circle talks about Zookeeper,Amabri which supports Spark job scheduling and resourcing..
- In last Outer circle , we have other system like Flume,Scoop,NoSQL DB’,Hadoop File system,RDBMS..etc which works with Spark together for different use cases..

SPARK Components:
SPARK CORE / SPARK SQL /SPARK Streaming/SPARK MLLIB /SPARK GRAPHX
Apache Spark Core:Spark Core consists of general execution engine for spark platform that all required by other functionality which is built upon as per the requirement approach. It provides in-built memory computing and referencing datasets stored in external storage systems.
Spark SQL:
Spark SQL is a component on top of Spark Core that introduces a new set of data abstraction called Schema RDD, which provides support for both the structured and semi-structured data
Spark Streaming:
This component allows Spark to process real-time streaming data. It provides an API to manipulate data streams that matches with RDD API. It allows the programmers to understand the project and switch through the applications that manipulate the data and giving outcome in real-time. Similar to Spark Core, Spark Streaming strives to make the system fault-tolerant and scalable.
MLlib (Machine Learning Library):
Apache Spark is equipped with a rich library known as MLlib. This library contains a wide array of machine learning algorithms, classification, clustering and collaboration filters, etc. It also includes few lower-level primitives
GraphX:
Spark also comes with a library to manipulate the graphs and performing computations, called as GraphX. Just like Spark Streaming and Spark SQL, GraphX also extends Spark RDD API which creates a directed graph. It also contains numerous operators in order to manipulate the graphs along with graph algorithms.
Now lets have a deep dive in SPARK and understand the SPARK Core.
SPARK Core::
Spark Core is the base of the whole project. It provides distributed task dispatching, scheduling, and basic I/O functionalities. Spark uses a specialized fundamental data structure known as RDD (Resilient Distributed Datasets) that is a logical collection of data partitioned
across machines.
What is RDD:
RDD is immutable distributed collection of objects.Users create RDDs in two ways: by loading an external dataset, or by distributing a collection of objects (e.g., a list or set) in their driver program.
An RDD is, essentially, the Spark representation of a set of data, spread across multiple machines, with APIs to let you act on it. An RDD could come from any datasource, e.g. text files, a database via JDBC, etc.
RDD is a logical reference of a dataset which is partitioned across many server machines in the cluster. RDDs are Immutable and are self recovered in case of failure.
Types of RDD:
- HadoopRDD
- FilteredRDD
- mappedRDD
- PairRDD
- ShuffledRDD
- UnionRDD
- PythonRDD
- DoubleRDD
- JDBCRDD
- JsonRDD
- SchemaRDD
- VertexRDD
- EdgeRDD
- CasandraRDD
- GEO RDD
- ESSpark
Two types of operations on RDDs: Transformations and Actions
• transformations are lazy (not computed immediately)
• the transformed RDD gets recomputed when an action is run on it
• however, an RDD can be persisted into storage in memory or disk
Lets talk about all the Transformation & Actions available in Scala.
Tranformation operations are also categories into two category
1) Narrow transformation – In Narrow transformation, all the elements that are required to compute the records in single partition live in the single partition of parent RDD. A limited subset of partition is used to calculate the result. Narrow transformations are the result of map(), filter()

1) Narrow transformation – In Narrow transformation, all the elements that are required to compute the records in single partition live in the single partition of parent RDD. A limited subset of partition is used to calculate the result. Narrow transformations are the result of map(), filter()
2)Wide transformation – In wide transformation, all the elements that are required to compute the records in the single partition may live in many partitions of parent RDD. The partition may live in many partitions of parent RDD. Wide transformations are the result of groupbyKey() and reducebyKey().
Transofrmation operations::
map(func):return a new distributed dataset formed by passing each element of the source through a function func.
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val b = a.map(x => (x.length, x))
b.values.collect
b.keys.collect
flatMap(func):Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item).
See the difference from below map & flatMap operation on same data.
See the difference from below map & flatMap operation on same data.
scala> val names = sc.parallelize(List("joe admon john smith mith bob")).map(_.split(" ")).collect
names: Array[Array[String]] = Array(Array(joe, admon, john, smith, mith, bob))
scala> val names = sc.parallelize(List("joe admon john smith mith bob")).flatMap(_.split(" ")).collect
names: Array[String] = Array(joe, admon, john, smith, mith, bob)
filter(func) :return a new dataset formed by selecting those elements of the source on which func returns true.
scala> val names = sc.parallelize(List("Spark","Hadoop","MapReduce","Pig","Spark2","Hadoop2","Pig")).filter(_.equals("Spark")).collect
names: Array[String] = Array(Spark)
sample(withReplacement,fraction, seed):sample a fraction fraction of the data, with or without replacement, using a given random number generator seed.
scala>val parallel = sc.parallelize(1 to 9)
parallel: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[470] at parallelize at <console>:12
scala>parallel.sample(true,.2).count
res403: Long = 3
scala>parallel.sample(true,.2).count
res404: Long = 2
//parallel.sample(true,.2).doesn't return the same sample size: that's because spark internally uses something called Bernoulli sampling for taking the sample.
union(a different rdd):return a new dataset that contains the union of the elements in the source dataset and the argument.
scala>val parallel = sc.parallelize(1 to 9)
parallel: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[477] at parallelize at <console>:12
scala>val par2 = sc.parallelize(5 to 15)
par2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[478] at parallelize at <console>:12
scala>parallel.union(par2).collect
res408: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15)
intersection(a different rdd):return a new dataset that contains the intesection of the elements in the source dataset and the argument.
scala> val parallel = sc.parallelize(1 to 9)
parallel: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[81] at parallelize at <console>:24
scala> val par2 = sc.parallelize(5 to 15)
par2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[82] at parallelize at <console>:24
scala> parallel.intersection(par2).collect
res72: Array[Int] = Array(6, 7, 8, 9, 5)
distinct([numTasks]):return a new dataset that contains the distinct elements of the source dataset.
scala> val parallel = sc.parallelize(1 to 9)
parallel: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[81] at parallelize at <console>:24
scala> val par2 = sc.parallelize(5 to 15)
par2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[82] at parallelize at <console>:24
scala> parallel.union(par2).distinct().collect
res74: Array[Int] = Array(12, 13, 1, 14, 2, 15, 3, 4, 5, 6, 7, 8, 9, 10, 11)
sortBy(func):Return this RDD sorted by the given key function
scala> val y = sc.parallelize(Array(5, 7, 1, 3, 2, 1))
y: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[103] at parallelize at <console>:24
scala> y.sortBy(c => c,false).collect
res82: Array[Int] = Array(7, 5, 3, 2, 1, 1)
scala> y.sortBy(c => c,true).collect
res83: Array[Int] = Array(1, 1, 2, 3, 5, 7
scala> val z = sc.parallelize(Array(("H", 10), ("A", 26), ("Z", 1), ("L", 5)))
z: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[119] at parallelize at <console>:24
scala> z.sortBy(c => c._1, true).collect
res84: Array[(String, Int)] = Array((A,26), (H,10), (L,5), (Z,1))
scala> z.sortBy(c => c._2, true).collect
res85: Array[(String, Int)] = Array((Z,1), (L,5), (H,10), (A,26))
mapPartitions(func):mapPartitions() can be used as an alternative to map() & foreach().mapPartitions() is called once for each Partition unlike map() & foreach() which is called for each element in the RDD.
scala> var parellal = sc.parallelize(1 to 9, 3)
parellal: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[130] at parallelize at <console>:24
scala> parellal.mapPartitions(x=>List(x.next).iterator).collect
res86: Array[Int] = Array(1, 4, 7)
scala> var parellal = sc.parallelize(1 to 9)
parellal: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[132] at parallelize at <console>:24
scala> parellal.mapPartitions(x=>List(x.next).iterator).collect
res87: Array[Int] = Array(1, 2, 4, 5, 7, 8)
mapPartitionsWithIndex:Return a new RDD by applying a function to each partition of this RDD, while tracking the index of the original partition.
scala> val nums = sc.parallelize(List(1,2,3,4,5,6), 2)
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[139] at parallelize at <console>:24
scala> def myfunc(index: Int, iter: Iterator[(Int)]) : Iterator[String] = {
iter.toList.map(x => "[index:" + index + ", val: " + x + "]").iterator
}
myfunc: (index: Int, iter: Iterator[Int])Iterator[String]
scala> nums.mapPartitionsWithIndex(myfunc).collect
res93: Array[String] = Array([index:0, val: 1], [index:0, val: 2], [index:0, val: 3], [index:1, val: 4], [index:1, val: 5], [index:1, val: 6])
groupBy , keyBy :
scala> val rdd = sc.parallelize(List((1,"apple"),(2,"banana"),(3,"lemon"),(4,"apple"),(1,"lemon")) )
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[0] at parallelize at <console>:27
scala> rdd.groupBy(_._1).collect
res8: Array[(Int, Iterable[(Int, String)])] = Array((4,CompactBuffer((4,apple))), (2,CompactBuffer((2,banana))), (1,CompactBuffer((1,apple), (1,lemon))), (3,CompactBuffer((3,lemon))))
scala> rdd.keyBy(_._1).collect
res10: Array[(Int, (Int, String))] = Array((1,(1,apple)), (2,(2,banana)), (3,(3,lemon)), (4,(4,apple)), (1,(1,lemon)))
scala> rdd.keyBy(_._2).collect
res11: Array[(String, (Int, String))] = Array((apple,(1,apple)), (banana,(2,banana)), (lemon,(3,lemon)), (apple,(4,apple)), (lemon,(1,lemon)))
zip, zipwithIndex:
//zip: Returns a list formed from this list and another iterable collection by combining
corresponding elements in pairs. If one of the two collections is longer than the
other, its remaining elements are ignored.
//zipWithIndex : Zips this list with its indices.
Returns: A new list containing pairs consisting of all elements of this list
paired with their index. Indices start at 0.
scala> val odds = sc.parallelize(List(1,3,5))
odds: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[17] at parallelize at <console>:27
scala> val evens = sc.parallelize(List(2,4,6))
evens: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[18] at parallelize at <console>:27
scala> val numbers = odds zip evens
numbers: org.apache.spark.rdd.RDD[(Int, Int)] = ZippedPartitionsRDD2[19] at zip at <console>:31
scala> numbers.collect
res12: Array[(Int, Int)] = Array((1,2), (3,4), (5,6))
scala> val evenswithIndex = evens zipWithIndex
evenswithIndex: org.apache.spark.rdd.RDD[(Int, Long)] = ZippedWithIndexRDD[20] at zipWithIndex at <console>:29
scala> evenswithIndex.collect
res13: Array[(Int, Long)] = Array((2,0), (4,1), (6,2))
colease /repartition :
scala> val numbers = sc.parallelize( 1 to 100,2)
numbers: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:27
scala> numbers.partitions.size
res4: Int = 2
scala> numbers.foreachPartition(x => println(x.toList))
List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50)
List(51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100)
scala> val numberIncreased = numbers.repartition(10)
numberIncreased: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[9] at repartition at <console>:29
scala> numberIncreased.partitions.size
res7: Int = 10
scala> numberIncreased.foreachPartition(x => println(x.toList))
List(3, 13, 23, 33, 43, 58, 68, 78, 88, 98)
List(8, 18, 28, 38, 48, 53, 63, 73, 83, 93)
List(9, 19, 29, 39, 49, 54, 64, 74, 84, 94)
List(1, 11, 21, 31, 41, 56, 66, 76, 86, 96)
List(10, 20, 30, 40, 50, 55, 65, 75, 85, 95)
List(5, 15, 25, 35, 45, 60, 70, 80, 90, 100)
List(6, 16, 26, 36, 46, 51, 61, 71, 81, 91)
List(2, 12, 22, 32, 42, 57, 67, 77, 87, 97)
List(7, 17, 27, 37, 47, 52, 62, 72, 82, 92)
List(4, 14, 24, 34, 44, 59, 69, 79, 89, 99)
scala> numberIncreased.coalesce(3)
res11: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[10] at coalesce at <console>:32
scala> res11.foreachPartition(x => println(x.toList))
List(2, 12, 22, 32, 42, 57, 67, 77, 87, 97, 4, 14, 24, 34, 44, 59, 69, 79, 89, 99, 7, 17, 27, 37, 47, 52, 62, 72, 82, 92)
List(3, 13, 23, 33, 43, 58, 68, 78, 88, 98, 5, 15, 25, 35, 45, 60, 70, 80, 90, 100, 8, 18, 28, 38, 48, 53, 63, 73, 83, 93)
List(10, 20, 30, 40, 50, 55, 65, 75, 85, 95, 1, 11, 21, 31, 41, 56, 66, 76, 86, 96, 6, 16, 26, 36, 46, 51, 61, 71, 81, 91, 9, 19, 29, 39, 49, 54, 64, 74, 84, 94)
groupByKey([numTasks])
when called on a dataset of (K, V) pairs, returns a dataset of (K, Seq[V]) pairs
reduceByKey(func,[numTasks])
when called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function.
sortByKey([ascending],[numTasks])
when called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order,as specified in the boolean ascending argument
join(otherDataset,[numTasks])
when called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key.
cogroup(otherDataset,[numTasks])
when called on datasets of type (K, V) and (K, W),returns a dataset of (K, Seq[V], Seq[W]) tuples –also called groupWith.
cartesian(otherDataset)
when called on datasets of types T and U, returns a cartesian.
Action operation::Unlike Transformations which produce RDDs, action functions produce a value back to the Spark driver program. Actions may trigger a previously constructed, lazy RDD to be evaluated.
reduce(func)
aggregate the elements of the dataset using a function func (which takes two arguments and returns one), and should also be commutative and associative so that it can be computed correctly in parallel
scala> val a = sc.parallelize(1 to 10, 3)
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[141] at parallelize at <console>:24
scala> a.reduce(_+_)
res94: Int = 55
scala> val names1 = sc.parallelize(List("abe", "abby", "apple"))
names1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[142] at parallelize at <console>:24
scala> names1.flatMap(k => List(k.size) ).reduce((t1,t2) => t1 + t2)
res96: Int = 12
collect()
return all the elements of the dataset as an array at the driver program – usually useful after a filter or other operation that returns a sufficiently small subset of the data.
scala> val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog", "Gnu", "Rat"), 2)
c: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[148] at parallelize at <console>:24
scala> c.collect
res100: Array[String] = Array(Gnu, Cat, Rat, Dog, Gnu, Rat)
scala> val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog", "Gnu", "Rat"), 2)
c: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[148] at parallelize at <console>:24
scala> c.collect
res100: Array[String] = Array(Gnu, Cat, Rat, Dog, Gnu, Rat)
collectAsMap:
It will return A Map object containg all key value pairs converted as Map.
scala> val alphanumerics = sc.parallelize(List((1,"a"),(2,"b"),(3,"c")))
alphanumerics: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[11] at parallelize at <console>:30
scala> alphanumerics.collectAsMap
res22: scala.collection.Map[Int,String] = Map(2 -> b, 1 -> a, 3 -> c)
count():
It will return a Long value that indicates how many elements presented in the RDD.
scala> val nums = sc.parallelize(List(1,5,3,9,4,0,2))
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at <console>:30
scala> nums.count
res21: Long = 7
first()
return the first element of the dataset – similar to take(1) .
scala> val names2 = sc.parallelize(List("apple", "beatty", "beatrice"))
names2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[159] at parallelize at <console>:24
scala> names2.first
res107: String = apple
take(n)
return an array with the first n elements of the dataset– currently not executed in parallel, instead the driver program computes all the elements.
scala> val nums = sc.parallelize(List(1,5,3,9,4,0,2))
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at <console>:30
scala> nums.take(4)
res20: Array[Int] = Array(1, 5, 3, 9)
takeOrdered:
It will return a Array with given numbers of ordered values in the RDD
scala> val nums = sc.parallelize(List(1,5,3,9,4,0,2))
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[9] at parallelize at <console>:30
scala> nums.takeOrdered(4)
res19: Array[Int] = Array(0, 1, 2, 3)
takeSample(withReplacement,fraction, seed)
return an array with a random sample of num elements of the dataset, with or without replacement, using the given random number generator seed.
saveAsTextFile(path)
write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system.
val a = sc.parallelize(1 to 10000, 3)
a.saveAsTextFile("mydata_a")
val x = sc.parallelize(List(1,2,3,4,5,6,6,7,9,8,10,21), 3)
x.saveAsTextFile("hdfs://localhost:8020/user/hadoop/test");
saveAsSequenceFile(path)
write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system.
countByKey()
only available on RDDs of type (K, V). Returns a `Map` of (K, Int) pairs with the count of each key.
foreach(func):
run a function func on each element of the dataset –usually done for side effects such as updating an
scala> val alphanumerics = sc.parallelize(List((1,"a"),(2,"b"),(3,"c")))
alphanumerics: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[15] at parallelize at <console>:27
scala> alphanumerics.foreach(println)
(2,b)
(1,a)
(3,c)
alphanumerics: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[15] at parallelize at <console>:27
scala> alphanumerics.foreach(println)
(2,b)
(1,a)
(3,c)
Persistence:
Spark can persist (or cache) a dataset in memory across operations Each node stores in memory any slices of it that it computes and reuses them in other actions on that dataset – often making future actions more than 10x faster.
The cache is fault-tolerant: if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it
Broadcast variables:
Broadcast variables let programmer keep a read-only variable cached on each machine rather than shipping a copy of it with tasks For example, to give every node a copy of a large input dataset efficiently Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost
Sample BigData-Spark Project done by using Spark-Core only:
Project-1 :
Project-2:
Big data engineering automation should understand the need of Data, and they should work to build more appropriate services to meet the requirements of their clients.
ReplyDeleteRedshift is the newdata warehouse solution from AWS. It is storage-optimized, which means that it is designed to perform queries against petabytes of data and thousands of tables with ease. It brings all the benefits of a massively parallel processing (MPP) system with the ease of use and reliability of an AWS service. Redshift is available in the AWS Free Tier, so you can try it out and see if it is the right solution for your business.
ReplyDelete