Exploring BigData Analytics Using SPARK in BigData World
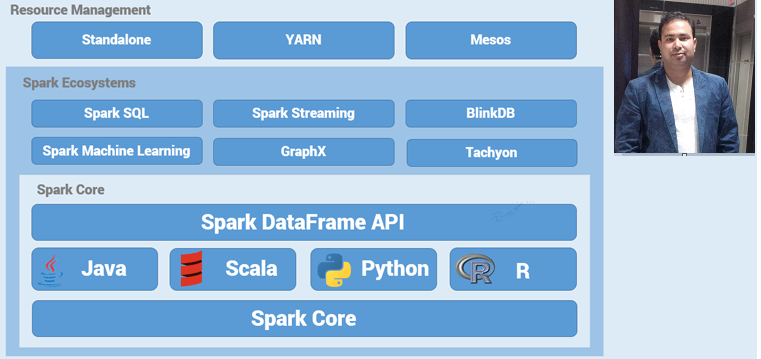
Hadoop ------------------------------ Map Reduce | Pig | Hive SPARK ------------------------------------------------ SQL & Hive | Streaming | ML | GraphX NOSQL ----------------------- MongoDB | HBase Data Ingestion Tools -------------------------- Sqoop | Flume BigData Project List Spark was developed in 2009 at UC Berkeley AMPLab , then open sourced in 2010, Spark has since become one of the largest OSS communities in big data,with over 200 contributors in 50+ organizations. “Organizations that are looking at big data challenges –including collection, ETL, storage, exploration and analytics -should consider Spark for its in memory performance and the breadth of its...